Back
Blogs
Scaling PostgreSQL to 800 Million ChatGPT Users: OpenAI's Production Database Architecture Deep Dive
26 Jan, 2026
•
05.00 PM
BLOG

Other Blogs

Engineering Precision Agriculture: Hands-On with Microsoft's Open-Source Farm of the Future AI Toolkit

Profiling Python Performance: Systematic Measurement with cProfile and SnakeViz
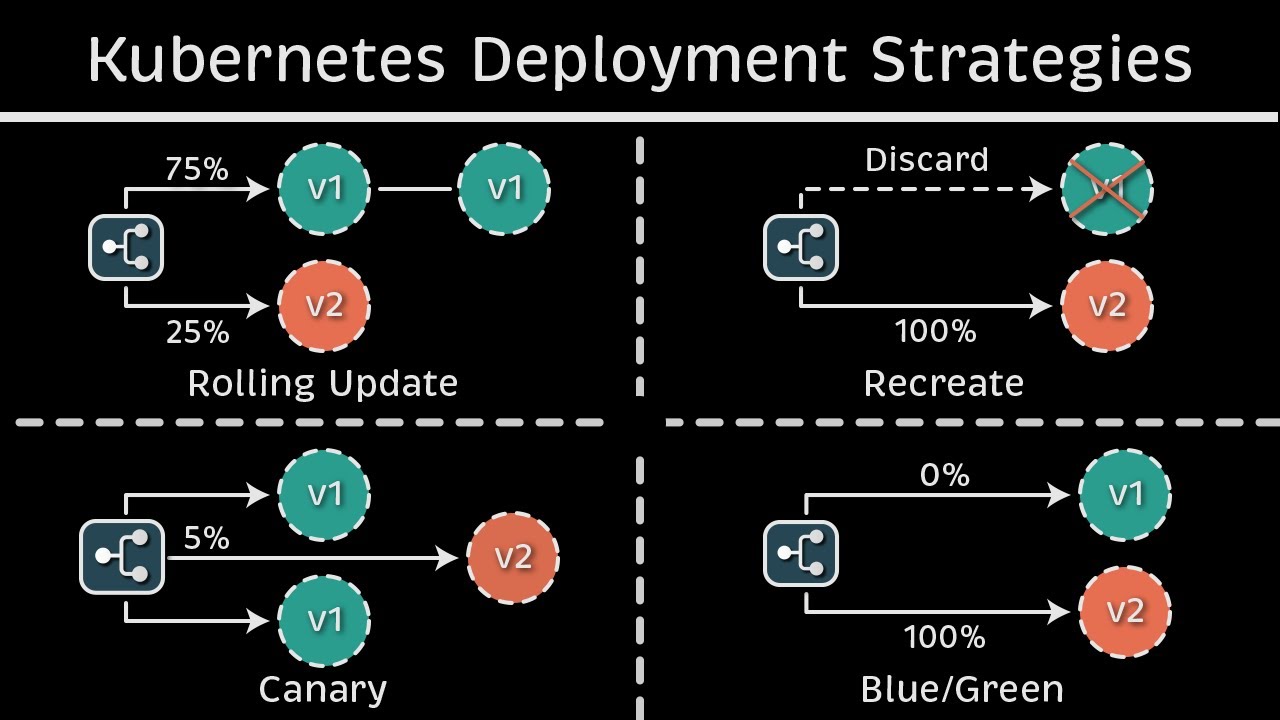
Is Kubernetes rolling update truly zero downtime ?

Business Development Executive Job Description: Top Duties and Qualifications

Sitecore JSS and Sitecore Docker